Working with Crawlers
Reading time 10 minutes
Overview
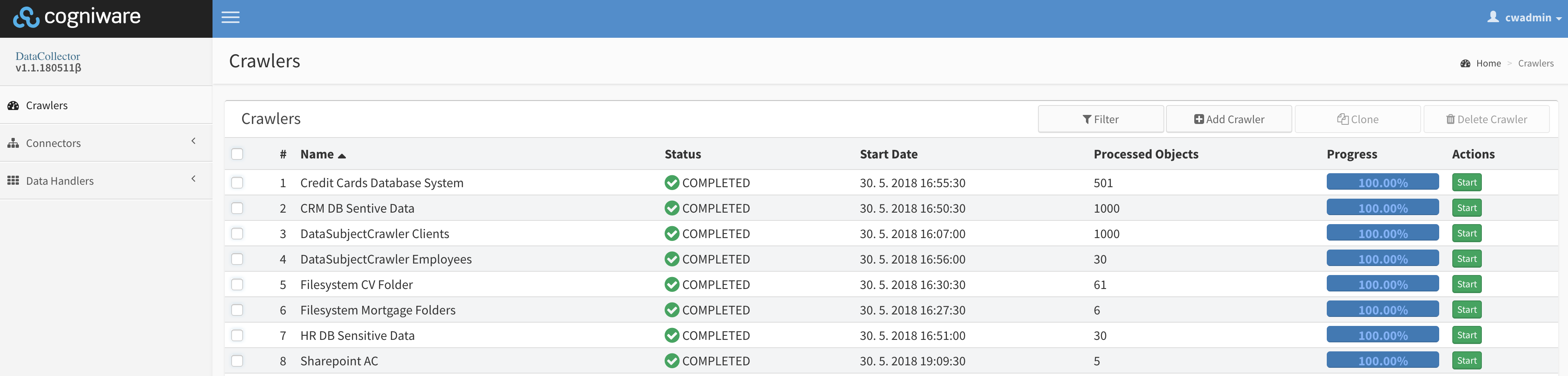
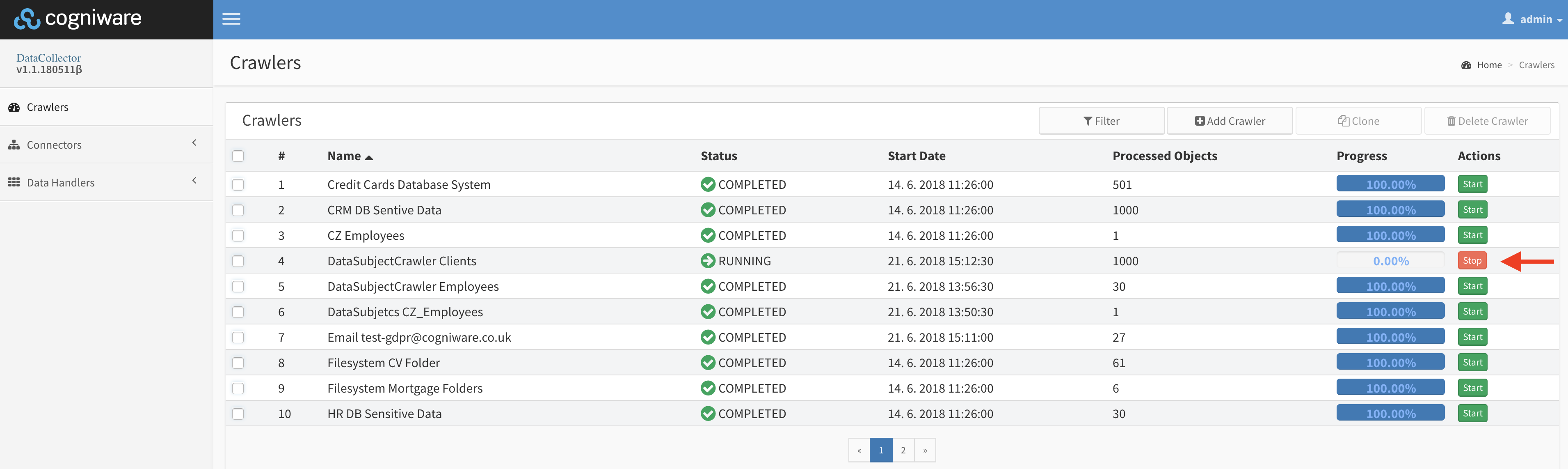
Crawlers are jobs defined by users and serve as definitions for crawling processes. Each crawler performs one crawling job and consists of connector, data handler and query definition. Crawlers are administered at Crawlers tab available in the menu navigation (on the left side of the screen) of the CWDC UI (please read Accessing CWDC to know how to connect). Each line represents one crawler and also displays basic overview of the crawler status, number of crawled records and control buttons to manually run and stop the Crawler.
Creating a new crawler
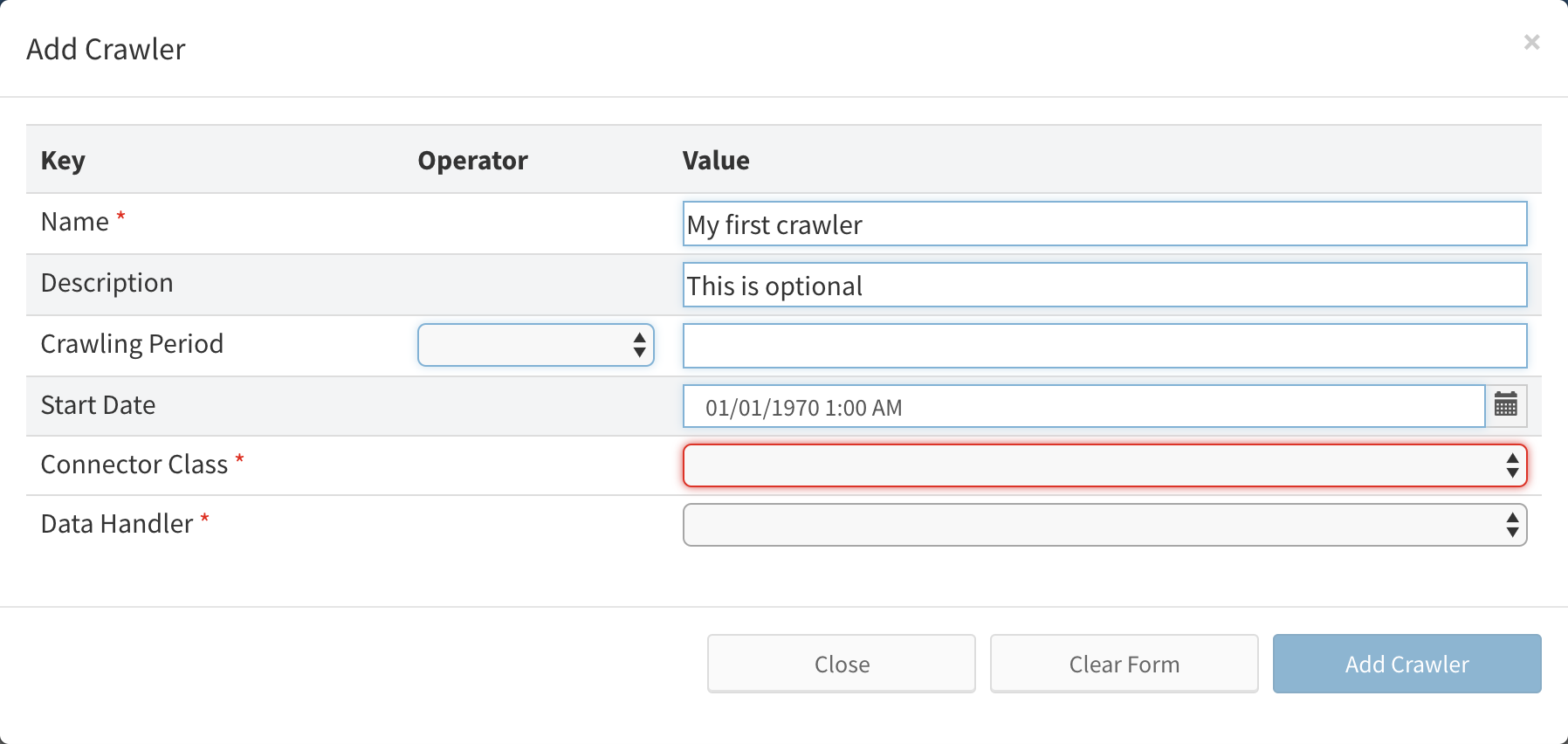
Click the Add Crawler button at Crawlers tab. New crawler definition form will appear.
Common crawler attributes
Fill in the Name.
GDPR Explorer hint
The Crawler name is used as the identifier od the source system and is show in the dashboard view and in requests and tasks - use a name that will clearly identify the source.
Compulsory fields are labeled by red asterisk and red border of particular field.
Common fields for all crawlers are name, description, crawling period (in case of periodic crawling) and start date.
Periodic crawling
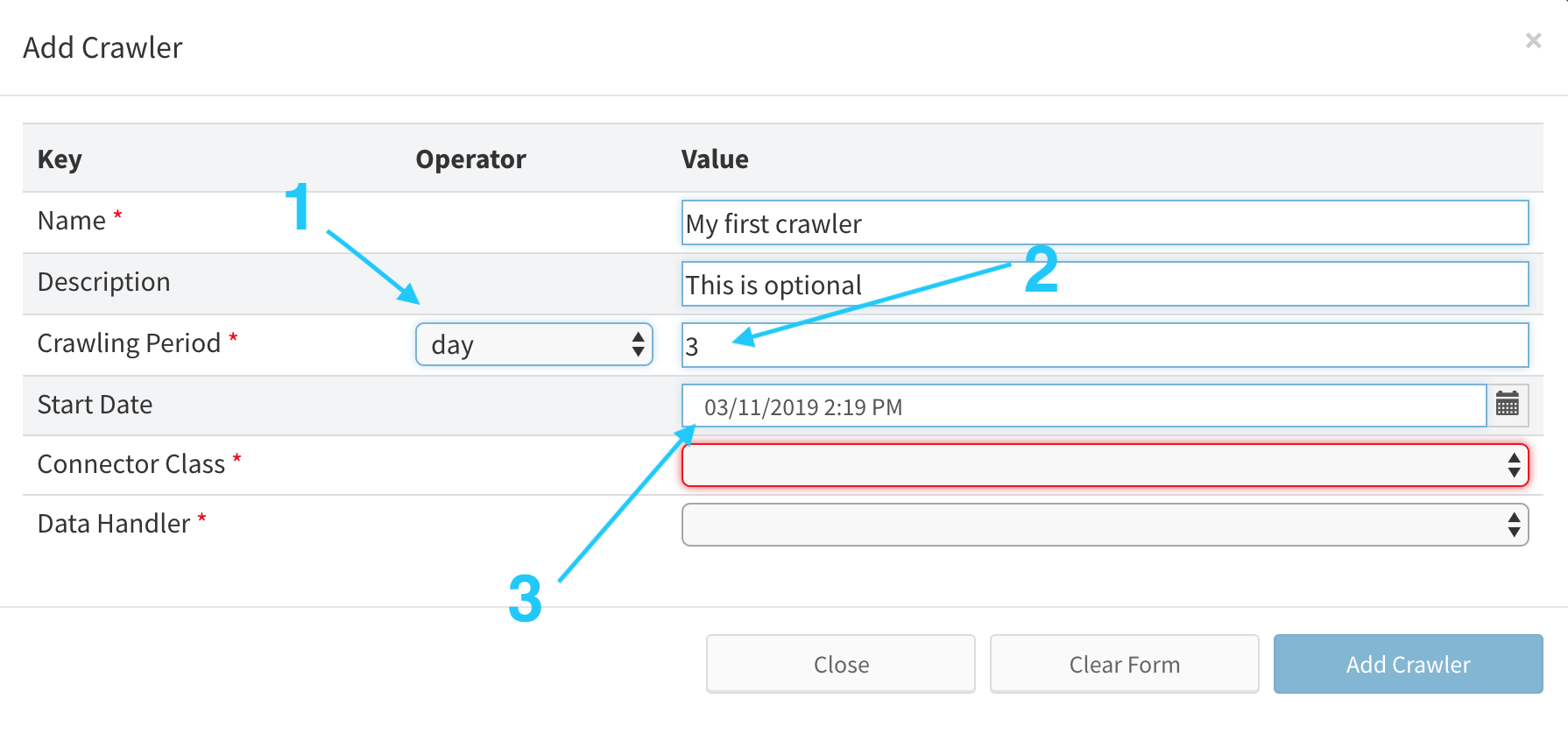
If you want to enable periodic crawling, choose the desired period and start date. The crawler will be automatically started based on these values. You can also leave the Start Date blank and start the crawler manually for the first time. Periodic Crawling can also be set-up or changed later.
| ID | Description |
|---|---|
| 1 | unit of periodicity (minute, hour, day, etc.) |
| 2 | multiplier of unit of periodicity (number, e.g. 15) |
| 3 | the date when crawling process will start |
Example: For example, this crawler will start crawling 11.3. 2019 every 3 days until schedule is changed, crawler is disabled or crawler is manually deleted
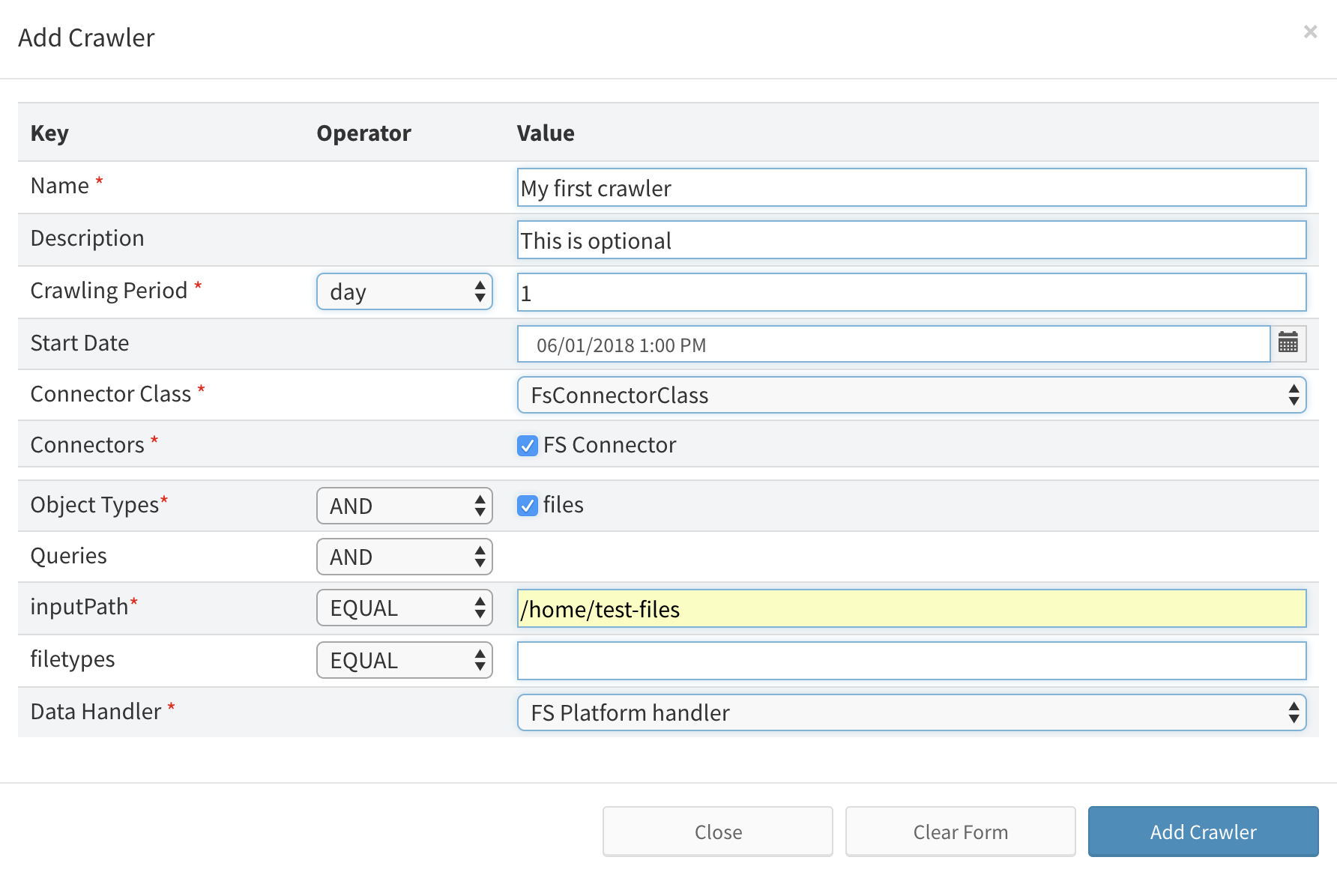
Configuring Crawler
Select the Connector class The form will be updated to correspond with the selected type of Connector.
Connector class determins the source system. To understand about the concept please read Getting started with CWDC.
Choose a Connector (connector definition containing one set of source connection credentials such as API keys). You need to create Connectors to your system before you create a Crawler for more information, please reffer to specific Crawler types.
Specify: Object Types (optional)
Objects to be crawled from source by crawler, if left blank all possible types of data are crawled.
Specify: Source Name, Source Type and other Crawler specific atributes.
These atributes are specific for each type of Crawler and you will find information about them in their respective documentation pages.
Source Name is certain identifier for particular connector resource, e.g. Facebook page identifier that is going to be crawled. Source Type specifies crawling job for particular connector and is further described in following chapters.
Choose a Data Handler
Data Handler specifies the target system. Data Handler needs to be created before creating the Crawler for more information, please reffer to specific Crawler types.
Example of fully filled Crawler form
Starting the Crawler for the first time
After the crawler is created it will appear in the list of exiting crawlers. Default status is Unknown. To start the crawler:
Click the Start button
Progress bar will show crawling progress and you can see the number of objects that were crawled in processed objects column of table.
Cloning Crawlers
If you need to create several new crawlers fast, you can use the cloning function.
Choose the Crawler to be cloned by marking the check box at the beginning of the row
Click on Clone button (located at the top of the list of Crawlers)
You can change the new Crawler attributes
Click Add Crawler
You have now sucessfuly created a new Crawler, you can continue by Starting the Crawler for the first time
Next topic: Nothing, you are good to go  .
.
Get me there: